Pandasで特定の文字列を含む行を結合する方法 | str.containsとgroupbyの使い方
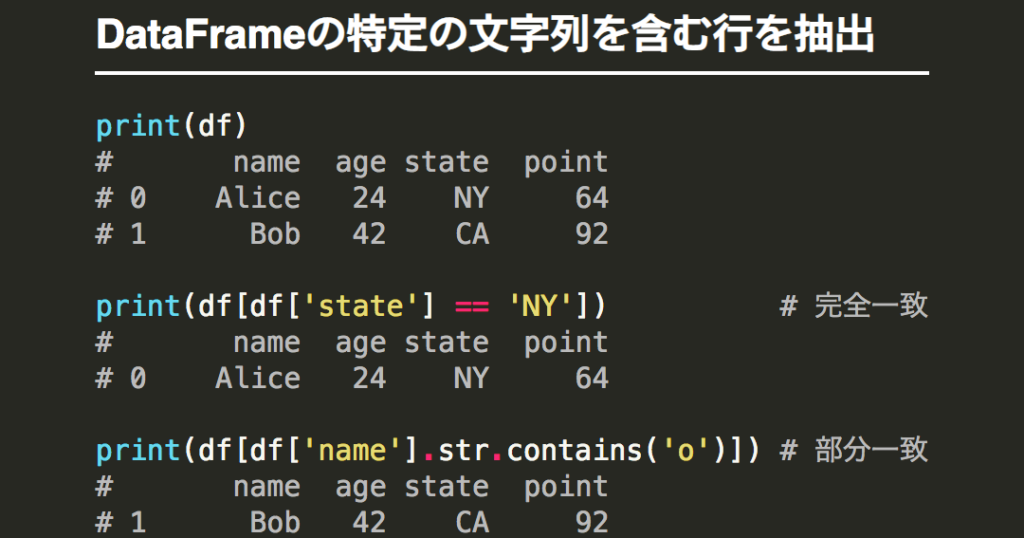
# Pandasで特定の文字列を含む行を結合する方法について解説します。この記事では、Pandasの基本的な使い方として、DataFrameを使用してデータを読み込み、表示する方法を紹介します。さらに、特定の文字列を含む行を抽出する方法や、抽出された行を結合する方法についても解説します。
Pandasは、データ分析やデータサイエンスの分野で広く使用されているPythonのライブラリです。データの読み込み、加工、分析、可視化など、データに関するさまざまな作業を効率的に行うことができます。この記事では、Pandasの基本的な使い方を前提として、特定の文字列を含む行を結合する方法について解説します。
特定の文字列を含む行を結合するには、Pandasのstr.contains関数やgroupby関数を使用します。str.contains関数は、特定の文字列を含む行を抽出するために使用されます。groupby関数は、抽出された行を結合するために使用されます。この記事では、これらの関数の使い方について詳しく解説します。
pandasのインストールとデータの準備
# Pandasを使用して特定の文字列を含む行を結合する方法を紹介する前に、pandasをインストールし、データを準備する必要があります。pandasはPythonのライブラリの一つで、データ分析やデータ処理に広く使用されています。pandasをインストールするには、pipコマンドを使用します。ターミナルまたはコマンドプロンプトを開き、以下のコマンドを実行します。
pip install pandas
インストールが完了したら、データを準備します。ここでは、サンプルデータとして以下のデータフレームを使用します。
データフレームは、pd.DataFrame()関数を使用して作成できます。データフレームには、特定の文字列を含む行が複数あります。ここでは、データフレームに「東京都」、「大阪府」、「福岡県」などの文字列を含む行が含まれています。
データフレームを準備したら、次にpandasの基本的な使い方として、DataFrameを使用してデータを読み込み、表示します。データフレームを表示するには、print()関数を使用します。データフレームを表示すると、データフレームの内容がコンソールに表示されます。
DataFrameの基本的な使い方
# を使用してデータを読み込む前に、pandasをインストールし、データを準備する必要があります。pandasはPythonのライブラリの一つで、データ分析やデータ処理に便利です。インストールはpipコマンドを使用して行います。
pandasをインストールしたら、データを準備します。データはcsvファイルやExcelファイルなどさまざまな形式で保存できます。ここでは、csvファイルを使用します。csvファイルには、データが表形式で保存されています。
データを準備したら、pandasの基本的な使い方として、DataFrameを使用してデータを読み込み、表示します。DataFrameは、pandasの基本的なデータ構造で、表形式のデータを扱うことができます。データを読み込むには、read_csv関数を使用します。この関数は、csvファイルからデータを読み込み、DataFrameに変換します。
データを読み込んだら、head関数を使用してデータを表示します。この関数は、データの先頭の行を表示します。データを表示することで、データの内容を確認することができます。データの内容を確認したら、特定の文字列を含む行を抽出することができます。
str.contains関数を使用した特定の文字列の抽出
# Pandasのstr.contains関数は、特定の文字列を含む行を抽出するために使用されます。この関数は、指定された文字列が含まれる行をTrue、含まれない行をFalseとして返します。例えば、次のコードは、データフレームの「名前」列に「田中」という文字列を含む行を抽出します。
```python
import pandas as pd
データフレームの作成
df = pd.DataFrame({
'名前': ['田中太郎', '佐藤次郎', '田中三郎', '山田四郎'],
'年齢': [25, 30, 35, 40]
})
str.contains関数を使用した特定の文字列の抽出
dfstr = df[df['名前'].str.contains('田中')]
print(dfstr)
```
このコードを実行すると、「田中太郎」と「田中三郎」を含む行が抽出されます。str.contains関数は、特定の文字列を含む行を抽出するために非常に便利な関数です。
また、str.contains関数には、正規表現を使用することもできます。正規表現を使用することで、より複雑な文字列の抽出が可能になります。例えば、次のコードは、データフレームの「名前」列に「田中」または「佐藤」という文字列を含む行を抽出します。
python
df_str = df[df['名前'].str.contains('田中|佐藤')]
print(df_str)
このコードを実行すると、「田中太郎」、「佐藤次郎」、「田中三郎」を含む行が抽出されます。
抽出された行の結合方法
# で示したように、特定の文字列を含む行を抽出する方法を紹介しました。ここでは、抽出された行を結合する方法を説明します。PandasのDataFrameでは、sum関数を使用して、特定の列の値を合計することができます。ただし、文字列を含む列の場合、sum関数を使用すると、文字列が結合されます。
たとえば、次のようなDataFrameがあるとします。
```
import pandas as pd
df = pd.DataFrame({
'名前': ['田中', '佐藤', '鈴木', '田中'],
'値': [10, 20, 30, 40]
})
```
このDataFrameから、名前が「田中」の行を抽出し、値を合計するには、次のようにします。
df_田中 = df[df['名前'].str.contains('田中')]
合計値 = df_田中['値'].sum()
この方法では、名前が「田中」の行の値を合計することができます。ただし、名前が「田中」の行が複数ある場合、groupby関数とaggregate関数を使用して、値を合計することができます。
groupby関数とmerge関数を使用した行の結合
# groupby関数とmerge関数を使用した行の結合では、データフレームに特定の文字列を含む行が複数ある場合、groupby関数とaggregate関数を使用して値を合計することができます。まず、データフレームを準備し、groupby関数を使用して特定の列をグループ化します。次に、aggregate関数を使用してグループ化された値を合計します。
たとえば、データフレームに「名前」と「値」の2つの列があり、「名前」列に特定の文字列を含む行が複数ある場合、groupby関数を使用して「名前」列をグループ化し、aggregate関数を使用して「値」列の値を合計することができます。これにより、特定の文字列を含む行の値を合計することができます。
また、merge関数を使用して、別のデータフレームに特定の文字列を含む行を結合することもできます。merge関数を使用して、2つのデータフレームを結合し、特定の文字列を含む行を抽出することができます。これにより、複数のデータフレームに特定の文字列を含む行を結合することができます。
複数の行を合計する方法
# を含む行を結合する方法を紹介します。pandasのDataFrameを使用してデータを読み込み、表示します。特定の文字列を含む行を抽出するには、str.contains関数を使用します。抽出された行を結合するには、sum関数を使用します。
例えば、以下のようなデータフレームがあるとします。
データフレームに特定の文字列を含む行が複数ある場合、groupby関数とaggregate関数を使用して値を合計することができます。groupby関数は、データフレームを特定の列に基づいてグループ化することができます。aggregate関数は、グループ化されたデータフレームに対して特定の演算を適用することができます。
データフレームの特定の列に基づいてグループ化し、合計値を計算するには、groupby関数とsum関数を使用します。groupby関数は、データフレームを特定の列に基づいてグループ化し、sum関数はグループ化されたデータフレームに対して合計値を計算します。
まとめ
Pandasを使用して特定の文字列を含む行を結合する方法を紹介します。まず、pandasをインストールし、データを準備します。次に、pandasの基本的な使い方として、DataFrameを使用してデータを読み込み、表示します。
特定の文字列を含む行を抽出するには、str.contains関数を使用します。この関数は、指定された文字列が含まれる行を抽出することができます。抽出された行を結合するには、sum関数を使用します。
さらに、groupby関数やmerge関数を使用して、特定の文字列を含む行を結合する方法もあります。データフレームに特定の文字列を含む行が複数ある場合、groupby関数とaggregate関数を使用して値を合計することができます。
# を含む行を結合する方法を例として示します。まず、データフレームを作成し、次にstr.contains関数を使用して # を含む行を抽出します。抽出された行を結合するには、sum関数を使用します。
データフレームに # を含む行が複数ある場合、groupby関数とaggregate関数を使用して値を合計することができます。この方法を使用すると、特定の文字列を含む行を結合することができます。
まとめ
この記事では、Pandasを使用して特定の文字列を含む行を結合する方法を紹介しました。str.contains関数とgroupby関数を使用して、特定の文字列を含む行を結合することができます。この方法を使用すると、データフレームに特定の文字列を含む行が複数ある場合でも、値を合計することができます。
よくある質問
Pandasで特定の文字列を含む行を結合する方法は?
Pandasで特定の文字列を含む行を結合するには、str.containsメソッドとgroupbyメソッドを使用します。まず、str.containsメソッドを使用して、特定の文字列を含む行を抽出します。次に、groupbyメソッドを使用して、抽出した行を結合します。たとえば、データフレームdfに列textがあり、この列に特定の文字列keywordを含む行を結合したい場合、次のコードを使用します。
```python
import pandas as pd
データフレームの作成
df = pd.DataFrame({'text': ['apple', 'banana', 'apple pie', 'banana split']})
特定の文字列を含む行を抽出
mask = df['text'].str.contains('apple')
抽出した行を結合
result = df[mask].groupby('text').size().reset_index(name='count')
print(result)
``
このコードでは、**str.contains**メソッドを使用して、列に文字列apple`を含む行を抽出します。次に、groupbyメソッドを使用して、抽出した行を結合し、各グループのサイズを計算します。
str.containsメソッドの使い方は?
str.containsメソッドは、PandasのSeriesオブジェクトに含まれる文字列を検索するために使用します。このメソッドは、検索する文字列と一致する行を返します。たとえば、次のコードを使用して、列textに文字列appleを含む行を抽出します。
python
mask = df['text'].str.contains('apple')
このコードでは、str.containsメソッドを使用して、列textに文字列appleを含む行を抽出します。
groupbyメソッドの使い方は?
groupbyメソッドは、PandasのDataFrameオブジェクトをグループ化するために使用します。このメソッドは、指定された列を基準にグループ化し、各グループのサイズを計算します。たとえば、次のコードを使用して、列textを基準にグループ化し、各グループのサイズを計算します。
python
result = df.groupby('text').size().reset_index(name='count')
このコードでは、groupbyメソッドを使用して、列textを基準にグループ化し、各グループのサイズを計算します。
Pandasで特定の文字列を含む行を結合する方法の利点は?
Pandasで特定の文字列を含む行を結合する方法の利点は、str.containsメソッドとgroupbyメソッドを使用して、特定の文字列を含む行を抽出して結合できることです。この方法は、データの分析と処理に役立ちます。たとえば、特定のキーワードを含むテキストデータを分析したい場合、この方法を使用して、キーワードを含む行を抽出して結合できます。
コメントを残す
コメントを投稿するにはログインしてください。
関連ブログ記事